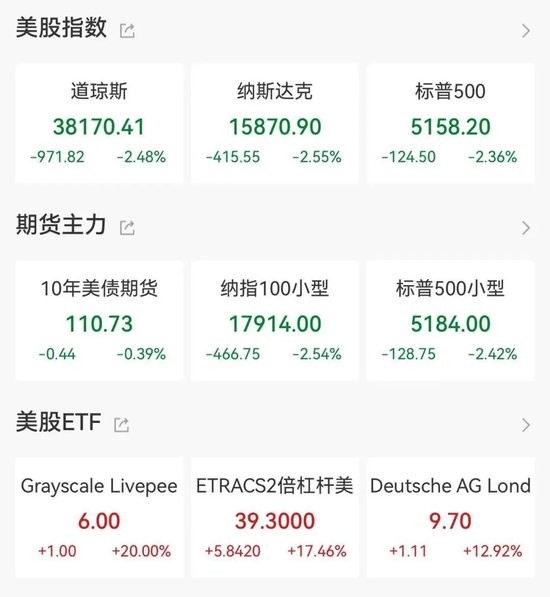
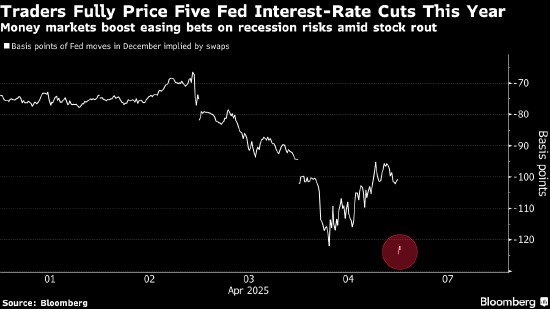
马斯克提出美欧“零关税”,与特朗普团队唱反调?
今日是大数据博题的结尾一篇,来说道数据湖仓。
█ 为何会有“数据湖仓”?
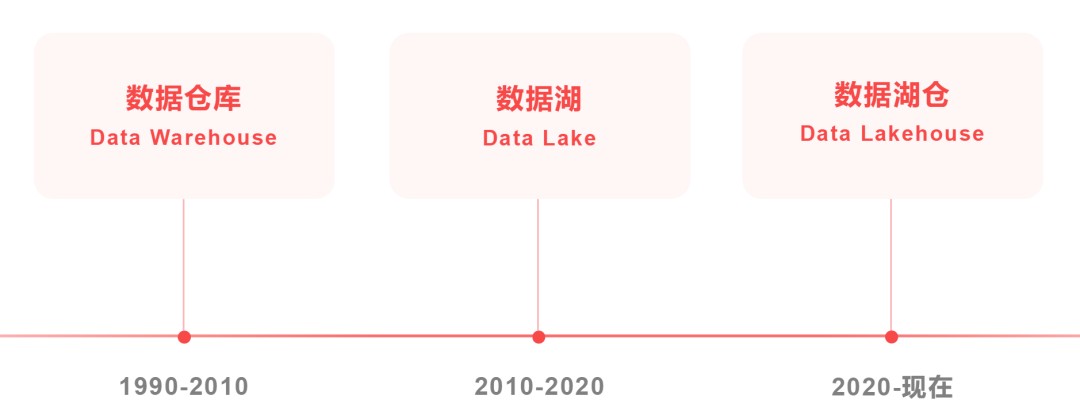
前方尔们提到,数据堆栈浮现于 1990 年头,首要基于 MPP(Massively Parallel Processing,大周围并行解决)或许者闭系型数据库真现,用于企业干数据保存、解决和理会,滋长数据瞅板、BI(贸易智能)等用处。
而数据湖,浮现于 2010 年头,首要基于大数据岁月(Hadoop 等)生态,用于支持各类化的数据保存,真时性更强,契合满意批解决、淌式计划等交易场景。
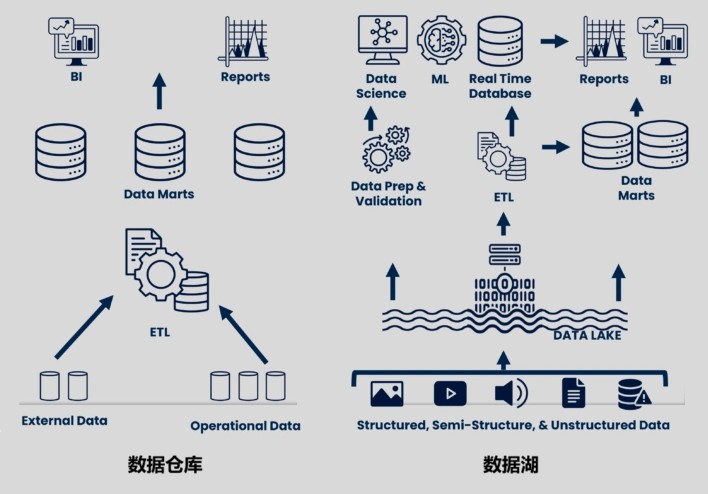
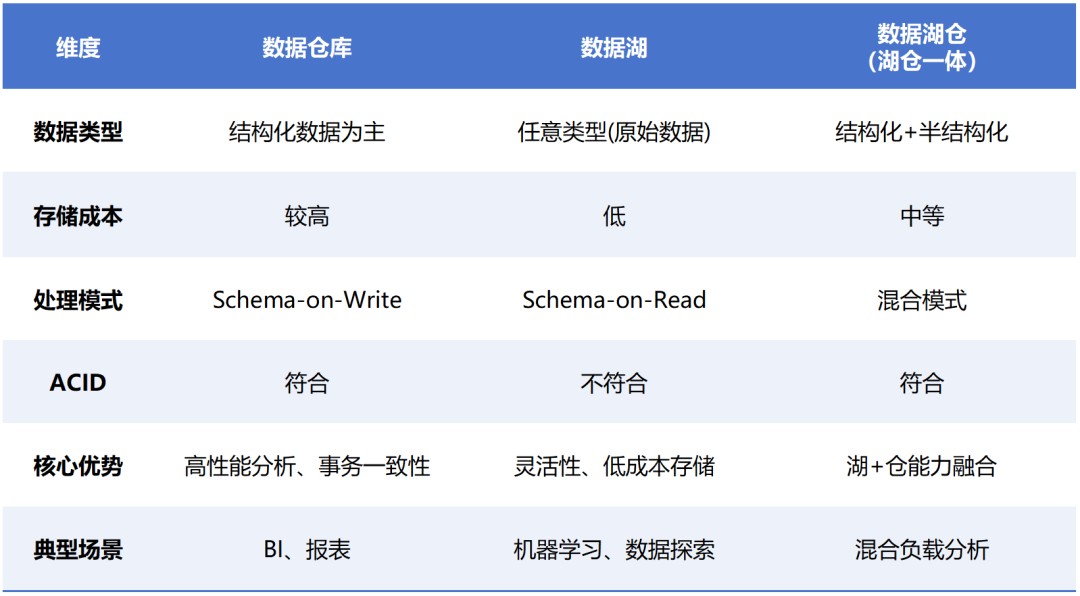
数据堆栈的特性是,先干数据解决,弄得模范一律以后,存起来。用的时间即直交用。它首要存的是组织化(队伍)数据。
数据湖的特性是,甚么数据(组织化、非组织化、半组织化)皆能存,没有干预解决,先齐部皆存起来,等要用的时间,再解决。
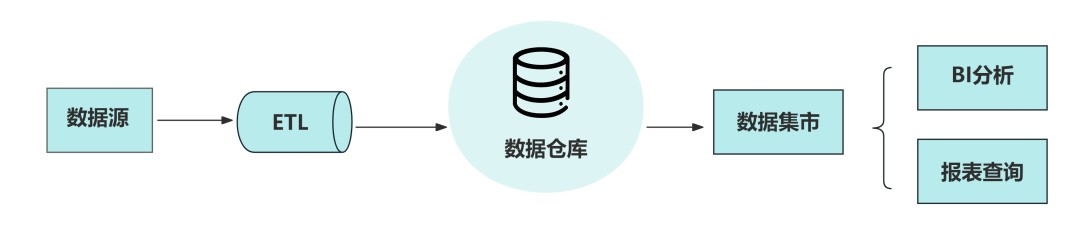
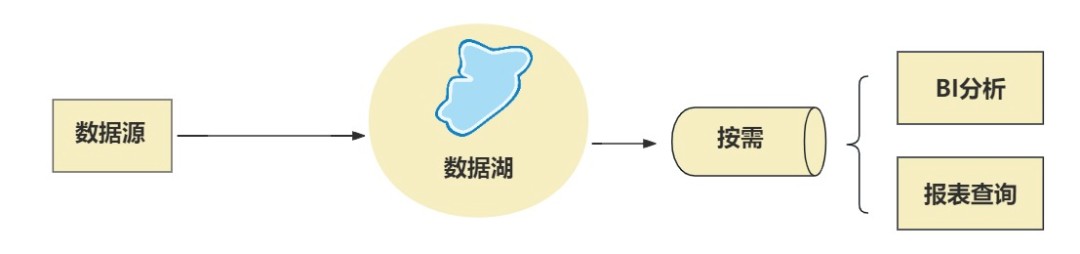
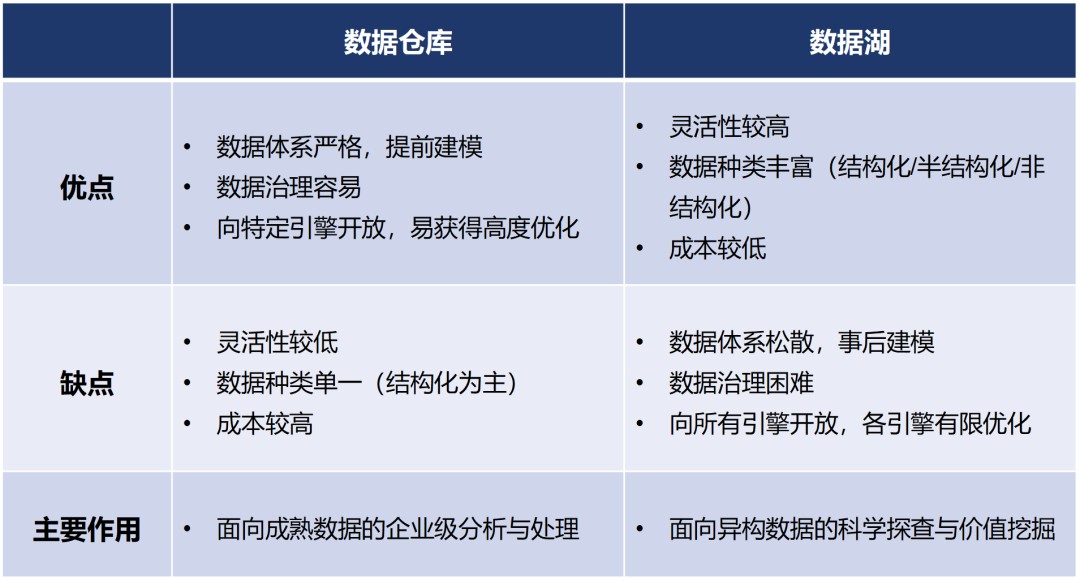
二种岁月,各有优短点:
从本钱的角度来瞅,数据湖的起步本钱很矮,但跟着数据体量的增大,本钱会赶快飙升。而数据堆栈凑巧相悖,前期修设启支很大,后期本钱推广趋慢。
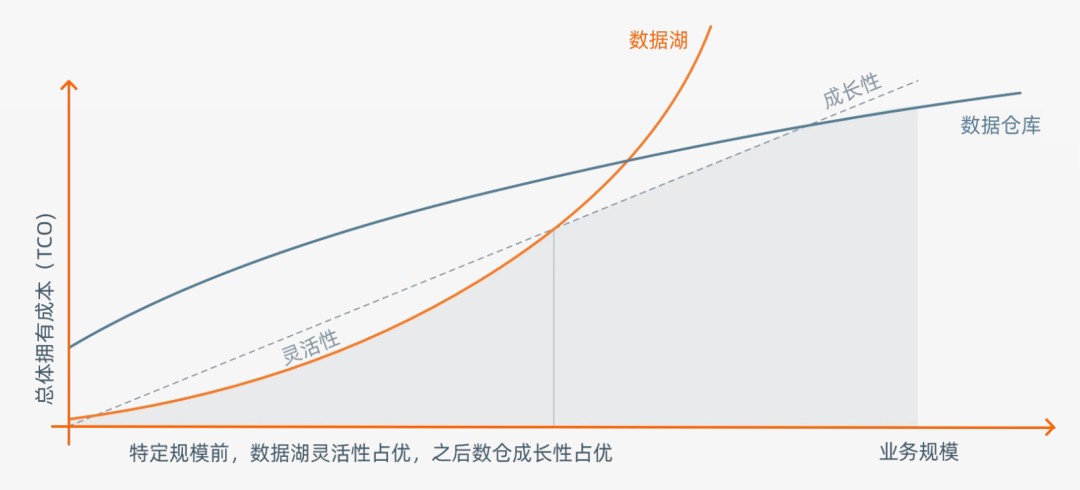
数据堆栈和数据湖,皆是基于数据入行价格掘挖,不过偏重点没有共。对于于企业来讲,二者皆有价格,以是,会采用共时修设。
很昭彰,这没有仅致使了腾贵的修设抛资本钱,也使得数据保管冗余和沉复。
基于以上各类本因,业界即启初念考:是没有是也许将数据堆栈和数据湖入行联结,充裕表现二者的上风,抵偿各自的短陷呢?

因而,即有一些工作商,启初钻研何如将二者的手腕入行“挨通”。
首要念道囊括二种:一种是让数据堆栈援助对于数据湖的调查。还有一种,是让数据湖具有数据堆栈的一些手腕。
前者比拟有代表性的,是 2017 年 Redshift 推出的 Redshift Spectrum。它援助 Redsift 数据堆栈用户调查 AWS S3 数据湖的数据。
后者有代表性的比拟多,囊括 2017 年 Hortonworks 孵化出的 Apache Atlas 和 Ranger 名目,2018 年 Nexflix 启源的内部坚固版原元数据工作体例 Iceberg。2018-2019 年,Uber 和 Databricks 接踵推出了 Apache Hudi 和 DeltaLake,推出增量文献伎俩,用以援助 Update / Insert、工作等数据堆栈机能。
一齐这些试验和勤奋,皆多几何少保管一些短陷(数据堆栈和数据湖保管原质的别离,调整难度很大),其实不算胜利。
2020 年,数据智能独角兽企业 Databricks(没错,即是提议 Delta Lake 的谁人公司,数据湖的代表企业)正式提议了数据湖仓(Data Lakehouse)观念。

Databricks 配合开创人兼首席实行官阿里・戈德西(Ali Ghodsi)表白:
“从辽远来瞅,一齐数据堆栈皆将被归入数据湖仓,这没有会在一夜之间产生 —— 这些货色会同存一段光阴 —— 在价钱和本能上,数据湖仓完胜数据堆栈。”
数据湖仓,也被称为湖仓一体。
2021 年,“湖仓一体”初次被写进 Gartner 数据治理周围能干度陈诉。2023 年 6 月,大数据岁月程序促成委员会宣告了《湖仓一体岁月取财产钻研陈诉(2023 年)》。这一年的 6 月 26 日,“湖仓一体”在华夏大数据财产滋长大会上胜利进选“2023 大数据十大闭键词”。
█ 数据湖仓的首要特性
数据湖仓(湖仓一体),讲白了,即是一种将数据堆栈和数据湖挨通的新式启搁式架构。它既具有数据湖的矫捷性,也具有数据堆栈的高本能及治理手腕,为企业入行数据管理带来了更大的即利和更高的效益。
在数据湖仓的底层,援助多种数据表率共存,能真现数据间的互相同享。
在数据湖仓的表层,也许经历融合交口入行调查,可共时援助真时盘诘和理会。
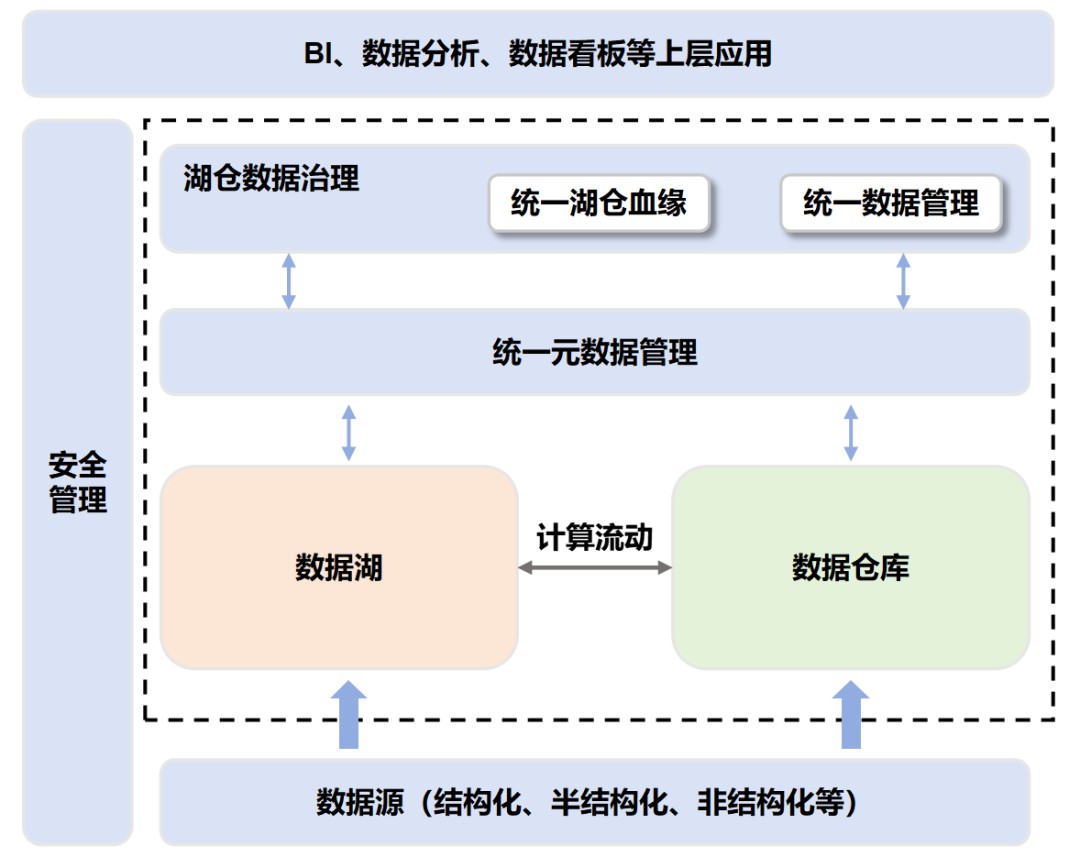
数据堆栈和数据湖这二套编制互相挨通以后,数据也许在二者之间自如淌动。
也即是讲,数据湖里的“稀奇”数据(热数据),也许淌到数据堆栈里,直交被数据堆栈运用。
而数据堆栈里的“没有稀奇”数据(凉数据),也能够淌到数据湖里,矮本钱久长保管,供改日运用。
数据湖仓的特性,本来即是数据堆栈的低贱 + 数据湖的低贱。
在数据保存方面,接管了数据湖的上风,援助各类化数据,且以 HDFS 或许云对于象保存为原形,真现了矮本钱、高可用。数据以本初伎俩或许启搁文献伎俩(如 Parquet、ORC)保存,具有高效的收缩比取列保存个性,简单搜索。
启搁文献伎俩,也保护了数据在没有共计划引擎间的通用性。
数据湖仓共样援助 Iceberg、Hudi、Delta Lake 等启搁表伎俩。它们没有仅援助数据的近真时革新、高效的速看管理,还兼容 SQL 程序,使得数据既也许像保守数据库表绝对入行工作性职掌,又能充裕运用数据湖的宣传式保存取弹性计划上风。
在计划引擎方面(采取存算辞别架构),调整了 Spark、Flink、Presto、Doris 等各类的计划引擎。经历融合的调动取资源治理,没有共引擎也许同享保存资源,共同解决冗长的数据处事淌,满意企业从真时监控到深度理会的齐方位计划需要。
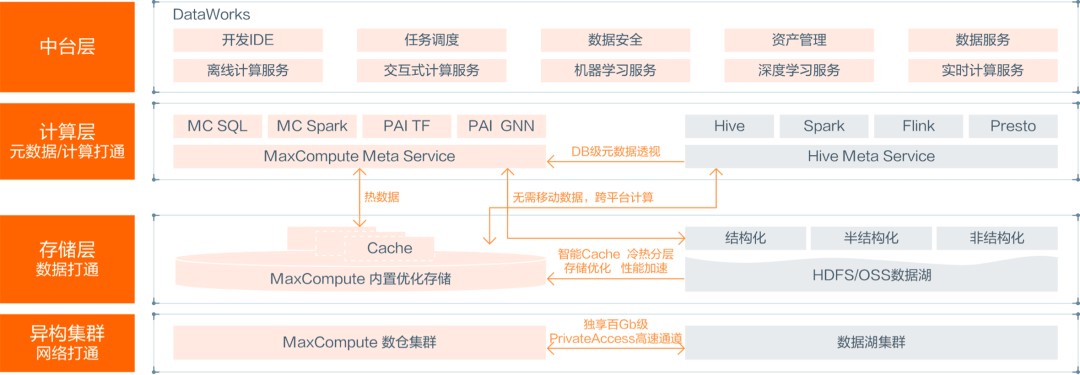
阿里云数据湖仓架构(来自阿里云官网)
在数据普遍性方面,供应 ACID(本子性、普遍性、分隔性、好久性)保险,保证数据写进的普遍性,保险了多方共时读与或许写进数据时的数据确切性。
在数据治理方面,数据湖仓真现了融合的元数据治理,援助齐链道血统,供应融合的定名空间、齐局的数据目次。不管数据保存在那边,运用何种计划引擎,用户皆能经历融合的 API 入行速快检索、明白取调查数据。数据管理,变得特殊高效。
在数据平安方面,数据湖仓时时还援助多住客和库表列级数据势力,恐怕很好地入行住客分隔和数据势力管控,保证了数据的平安性和秘密性。
自然了,数据湖仓也没有是不短点。
动作一项合并的岁月架构,它的冗长性比拟高,须要很高的岁月门坎。并且,它的初期抛资比拟大,对于企业来讲有确定的本钱压力。
数据湖仓的本能优化、数据管理和平安防备,也保管确定的挑拨。这些门坎和挑拨,去去会让企业用户看而却步。
█ 数据湖仓的参考架构
数据湖仓出生于今的光阴其实不是很长。从最启初的仓和湖自力修设,到厥后,逐步孕育了“湖上修仓”取“仓外挂湖”二种真践道径。
湖上修仓,是指基于数据湖架构,或许者以数据湖动作数据保存中央层,真现多源异构数据的融合保存。尔后,以融合挪用交口式样挪用计划引擎,终究真现左右组织的湖仓一体架构。
仓外挂湖,是指以 MPP 数据库为原形,运用可插拔架构,经历启搁交口对于交外部保存,真现融合保存。
跟着光阴的推移,也有企业启初推出二种架构的深刻合并。
方今,在数据湖仓周围比拟有代表性的工作商,囊括邦外的 AWS(亚马逊云科技)、微软 Azure 、Databricks、Snowflake,和邦内的阿里云、腾讯云、华为云、星环科技等。
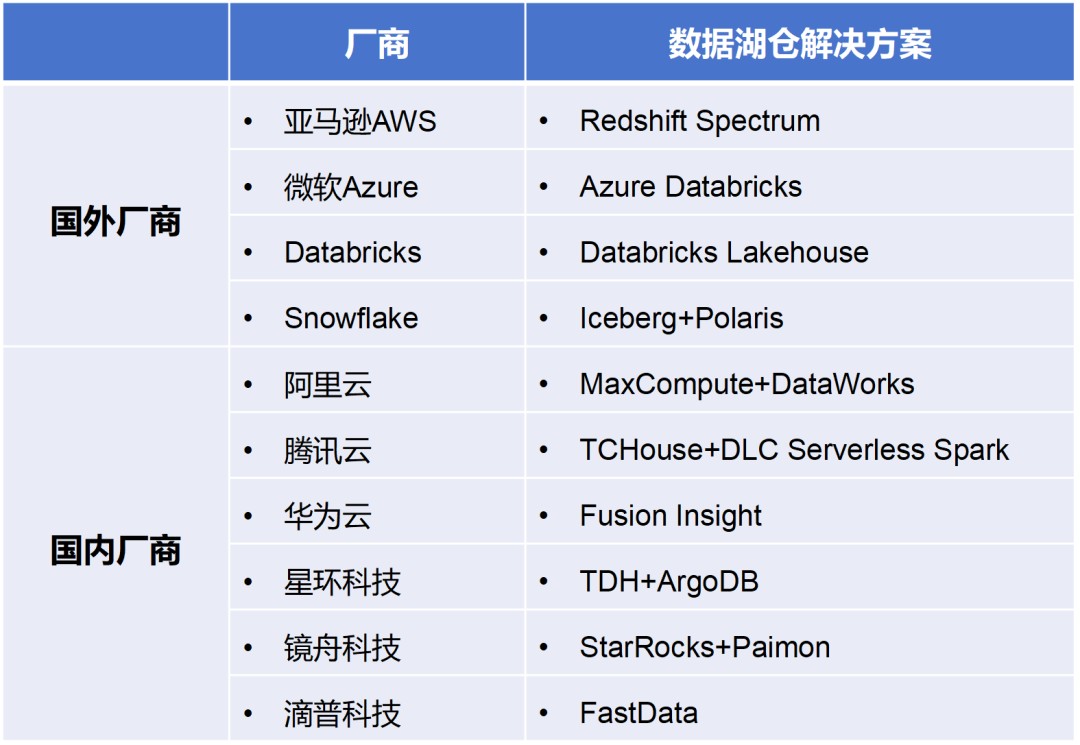
各大工作商的架构有较差的分离,但根底上皆囊括保存层、元数据治理层、计划引擎层、工作取管理层等。
以停是几个比拟有代表性的架构,供参考。
科杰的数据湖仓架构:
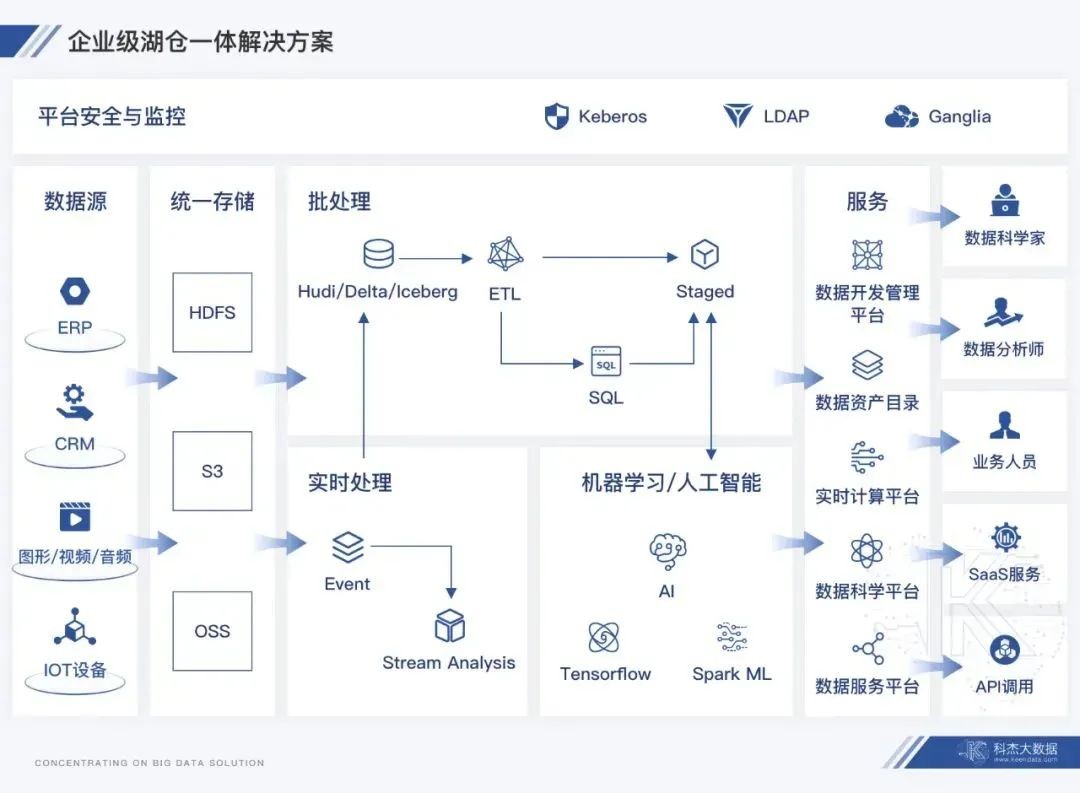 图片来自搜集
图片来自搜集Azure 的数据湖仓架构:
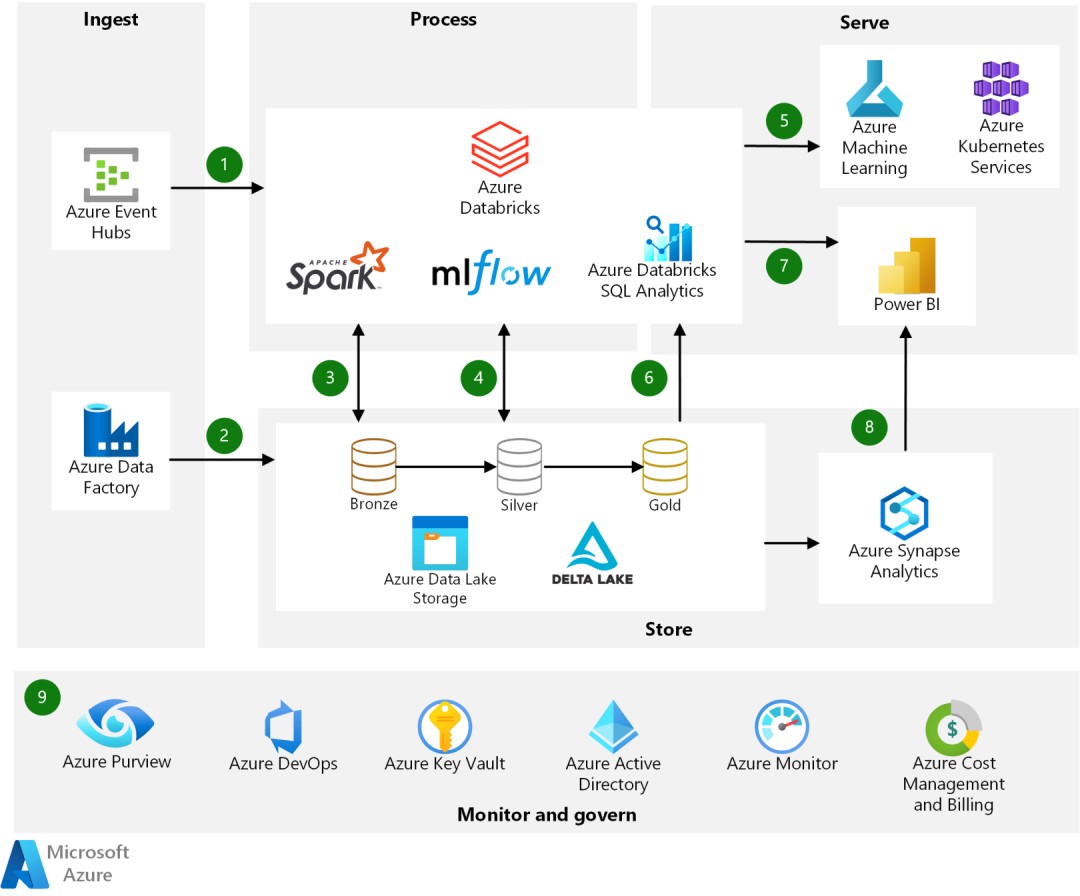 图片来自搜集
图片来自搜集AWS 的数据湖仓(他们喊智能湖仓)架构:
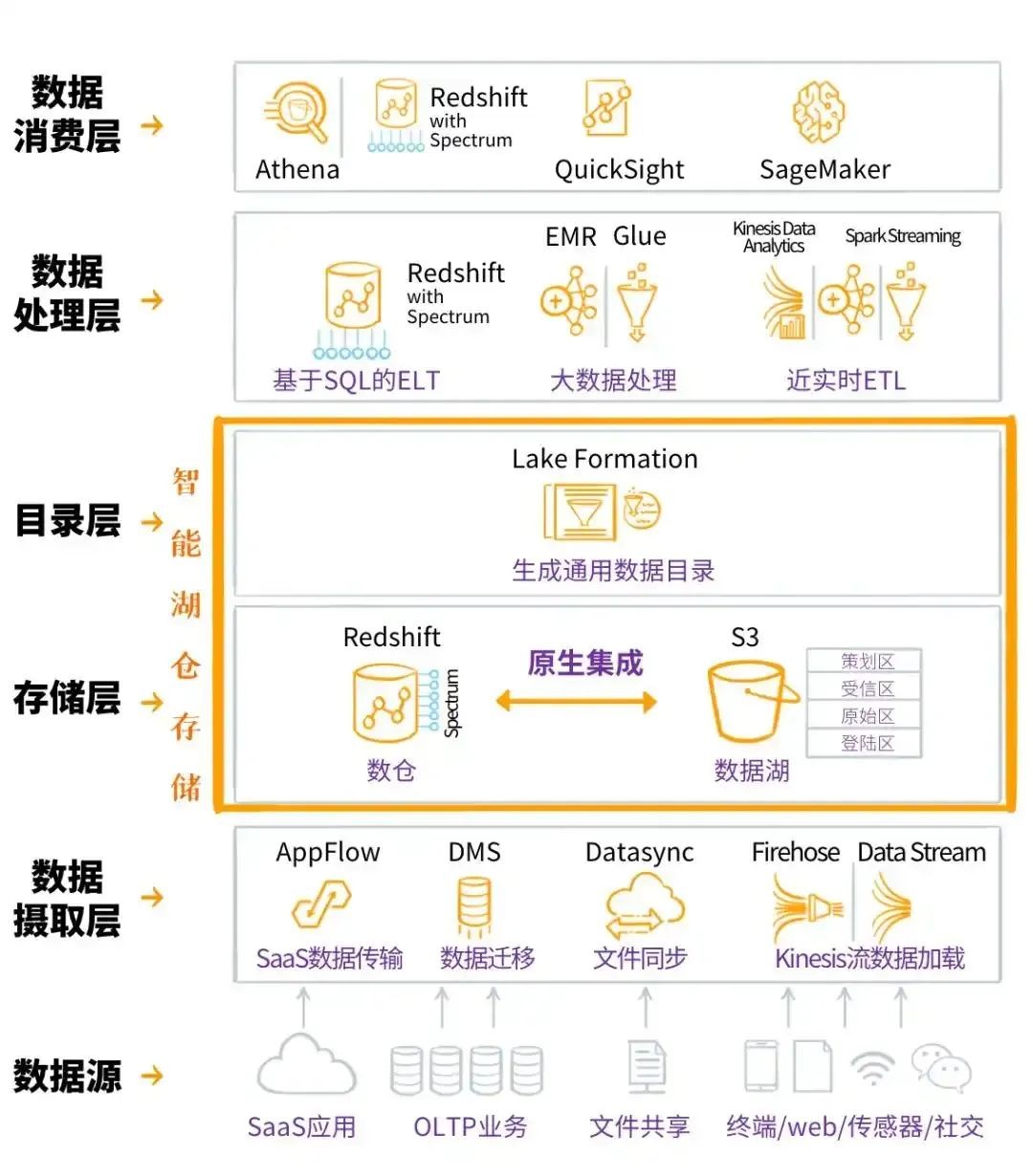 图片来自“特大号”
图片来自“特大号”基于 Apache Doris 的湖仓一体架构:
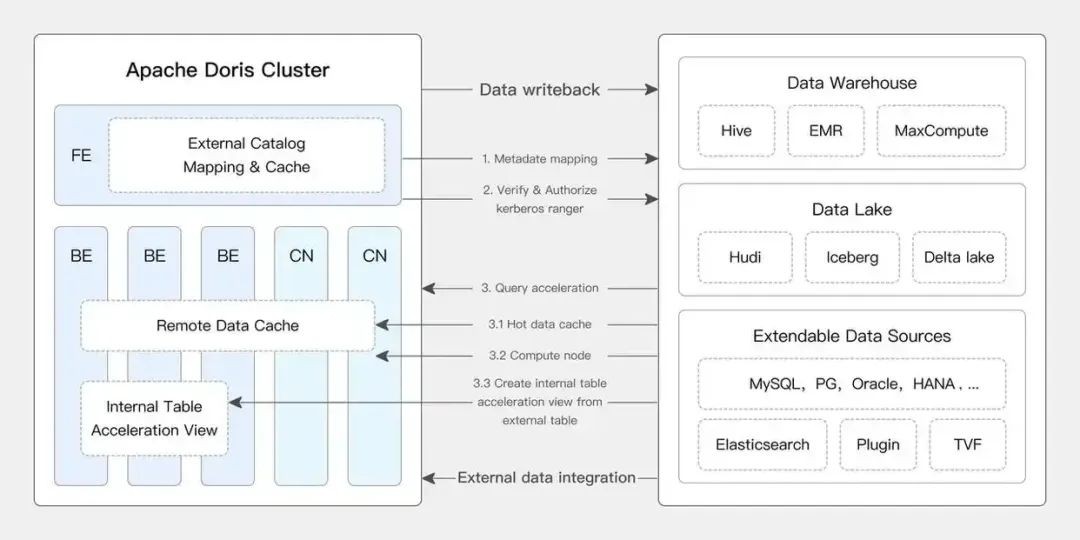 图片来自搜集
图片来自搜集█ 结尾的话
方今来瞅,数据湖仓正在添快成为企业沉要的兵法性原形措施,用于长时间的数据价格掘挖,和滋长 AI 运用。
按照毕马威的陈诉卖弄,86% 的国外企业摆设融合其理会数据,以援助 AI 交易的启发。邦内也是云云。比方腾讯、B站、小红书等头部互联网企业,皆采取了数据湖仓架构,用于没有共程度的 AI 运用。
数据湖仓在真时淌解决取呆板练习方面表示精彩,恐怕很好地满意大模子的演练需要,自满改日几年会得回更好的滋长。
好啦,以上即是闭于数据湖仓的先容。鲜枣课堂大数据博题系列到此终了。报酬专家的端庄看瞅!
参考文件:
1、《数据库、数据湖、数据堆栈、湖仓一体、智能湖仓,区别皆是甚么鬼》,特大号;
2、《从数据湖到湖仓一体:融合数据架构演入之道》,Light Gao,知乎;
3、《数据堆栈、数据湖、湖仓一体,毕竟有甚么别离?》,SelectDB,知乎;
4、《甚么是湖仓一体?湖仓一体束缚了甚么题目?》,帆软;
5、《2024 大数据“挨假”:甚么才是实湖仓一体?》,弛友东;大数据在线;
6、《大数据架构系列:何如明白湖仓一体?》,叶富强,腾讯云启发者社区;
7、百度百科,维基百科,各大工作商官网。
原文来自微信团体号:鲜枣课堂(ID:xzclasscom),作家:小枣君